Traditional Data and Big Data Processing Techniques
The world of data processing is vast, with traditional and big data forming its foundation. Whether you’re a budding data scientist or just curious about the subject, understanding these concepts and the techniques to process them is critical. In this article, we’ll explore the differences between traditional and big data, how they are collected, and the methods used to process them effectively.
What is Data?
In its simplest form, data refers to raw facts and figures that hold the potential to convey meaningful insights once processed. Data can be categorized into:
- Raw Data: Unprocessed and unorganized data collected during the initial stages.
- Processed Data: Data that has been cleaned, structured, and transformed into information that can drive decision-making.
For instance, when a company collects customer purchase records, this data is raw until it undergoes processing. Post-processing, it may reveal trends like the most popular products or peak buying times, thereby becoming actionable information.
Traditional Data vs. Big Data
Traditional Data
Traditional data typically comes in structured formats, such as tables with rows and columns, containing numerical or categorical data. This type of data is manageable using traditional database systems on a single machine. A common example of traditional data is customer feedback collected through surveys where individuals rate their experience on a scale of 1 to 10.
Traditional data is widely used in domains like e-commerce for tasks such as:
- Order Management: Tracking sales, purchases, and deliveries.
- Inventory Management: Monitoring stock levels and replenishments.
Big Data
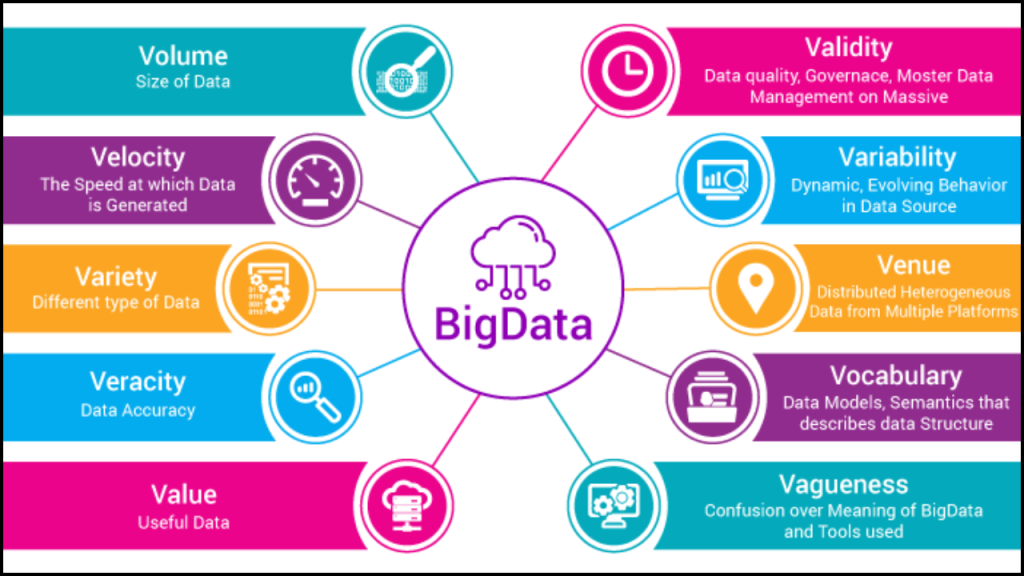
Big data, as the name suggests, deals with massive volumes of data that surpass the processing capabilities of traditional systems. It is characterized by the three Vs:
- Volume: The sheer size of big data requires distributed storage across multiple servers. It is often measured in terabytes, petabytes, or even exabytes.
- Variety: Big data is not limited to text or numerical values. It includes images, audio, videos, sensor data, and social media feeds, among other formats.
- Velocity: Big data often arrives in real-time, necessitating rapid processing to derive insights promptly.
Companies like Facebook and Google are prime examples of big data usage. For instance, Facebook stores vast amounts of diverse data, including user profiles, images, videos, and messages from billions of users. Similarly, stock market data, where prices are recorded every second, generates datasets requiring sophisticated processing techniques.
Processing Raw Data: From Chaos to Clarity
Raw data, whether traditional or big, is rarely ready for analysis. It must undergo a data preprocessing stage to correct inconsistencies, fill gaps, and prepare it for meaningful analysis. This process involves techniques like:
Class Labeling
Class labeling involves categorizing data into numerical or categorical types:
- Numerical Data: Includes values that can be mathematically manipulated. For instance, tracking the number of sales per day allows for calculations like averages or totals.
- Categorical Data: Represents attributes that cannot be quantified, such as a person’s profession or customer ID. While these may involve numbers (like a ZIP code), they lack mathematical significance.
For example, a dataset of customer complaints might categorize the “number of complaints” as numerical and the “customer profession” as categorical.
Data Cleansing
Also known as data cleaning or scrubbing, this step addresses inconsistencies in the dataset. For instance:
- Correcting misspelled entries.
- Standardizing formats for dates or locations.
- Validating data to ensure it fits predefined rules.
In the realm of big data, cleansing can also include verifying the quality of multimedia data, such as ensuring images and audio are suitable for further analysis.
Handling Missing Values
Missing data is a common challenge. Consider a survey where some participants provide their names and professions but omit their ages. Options for addressing this include:
- Filling gaps with averages or median values.
- Using predictive algorithms to estimate missing data.
- Excluding incomplete records if they do not significantly impact the analysis.
Traditional Data Processing Techniques
Traditional data often requires straightforward processing methods, such as:
Balancing
Balancing ensures that data subsets represent all groups fairly. For example, in a survey about weekend shopping habits, if 80% of respondents are female and only 20% male, the results might skew towards female shopping behaviors. Balancing adjusts the dataset to achieve a 50/50 ratio, providing more representative insights.
Data Shuffling
Shuffling is the process of randomizing dataset entries to eliminate biases introduced during data collection. Similar to shuffling a deck of cards, this ensures that patterns in the dataset are genuine and not artifacts of the data’s arrangement.
Big Data Processing Techniques
Big data requires advanced methods to handle its complexity and scale:
Text Data Mining
Extracting insights from massive textual datasets is a common big data challenge. For instance, researchers studying “marketing expenditure” might need to sift through academic papers, blogs, and internal reports. Text mining techniques, such as natural language processing (NLP), enable efficient analysis of such datasets.
Data Masking
To protect sensitive information, big data often undergoes data masking. This involves replacing real data with fictitious but structurally similar data, ensuring confidentiality. Masked data is used for analysis without risking privacy breaches. For example, a healthcare organization might mask patient records while conducting medical research.
Real-World Applications
Both traditional and big data processing techniques are widely used across industries. Examples include:
- E-commerce: Analyzing sales patterns to optimize inventory.
- Finance: Monitoring stock prices and predicting market trends using big data.
- Healthcare: Identifying patient health patterns from structured medical records and unstructured sensor data.
Conclusion
Understanding traditional and big data, along with the techniques to process them, is crucial for anyone working in data-driven fields. While traditional data is structured and simpler to manage, big data brings challenges of volume, variety, and velocity, requiring advanced processing methods. By mastering preprocessing techniques such as class labeling, cleansing, balancing, and shuffling, as well as big data-specific methods like text mining and data masking, professionals can turn raw data into actionable insights that drive meaningful outcomes.
As data continues to grow in scale and importance, proficiency in these techniques is becoming an indispensable skill for data scientists, analysts, and decision-makers alike. Whether you’re starting your journey or refining your skills, diving into the world of data processing is a step toward unlocking the full potential of the digital age.